

With many organizations using machine learning, every learner needs to have complete knowledge of algorithms. The most popular one is K-Nearest Neighbor (KNN) Algorithm.
KNN is a quite simple classification method that identifies which class has a sample by comparing it with other nearby points. Although it is quite basic to comprehend, this technique is effective enough to find out the class of an unidentified sample point.
This blog shall provide a complete overview of the KNN algorithm, how this Machine Learning algorithm works, its role in ML, and its advantages and disadvantages.
K-Nearest Neighbor (KNN) Algorithm: Overview
KNN algorithm identified the similarity between the new case and existing cases. Further, place the new case into the category that is the same as the available categories.
KNN algorithm contains the available data and then, classifies a new data point based on similarity. This means it becomes easier to classify data (when it appears) into a suitable category by applying the KNN algorithm.
Being a non-parametric algorithm, the KNN algorithm can be utilized for Classification and Regression. However, mostly it is utilized for Classification problems by AI professionals.
Fun Fact:
This algorithm is also known as a lazy learner algorithm. The reason behind it is it does not instantly learn from the training set. Rather, it stores the dataset and during classification, it works on the dataset.
Need for A KNN Algorithm
The KNN algorithm can easily compete with highly accurate models as it makes the most accurate predictions. Thus, using the KNN algorithm for applications that need high accuracy and not a human-readable model, is a wise choice.
Let us take an example of two categories - Category A and Category B. You have a new data point x1 and you need to find in which category the data point will lie.
Solution: Apply a KNN algorithm. With the assistance of KNN, you can identify the category of a specific dataset. Consider the below diagram:
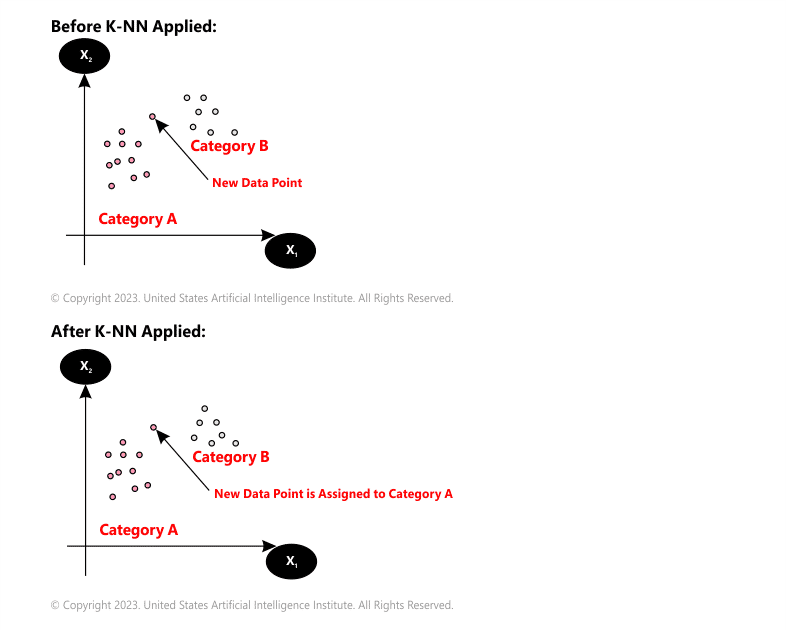
In almost all the ML certification programs, this algorithm is covered in detail in order to provide a complete understanding of it to the learners.
How Does KNN Algorithm Work?
Quick Steps of understand KNN algorithm workings:
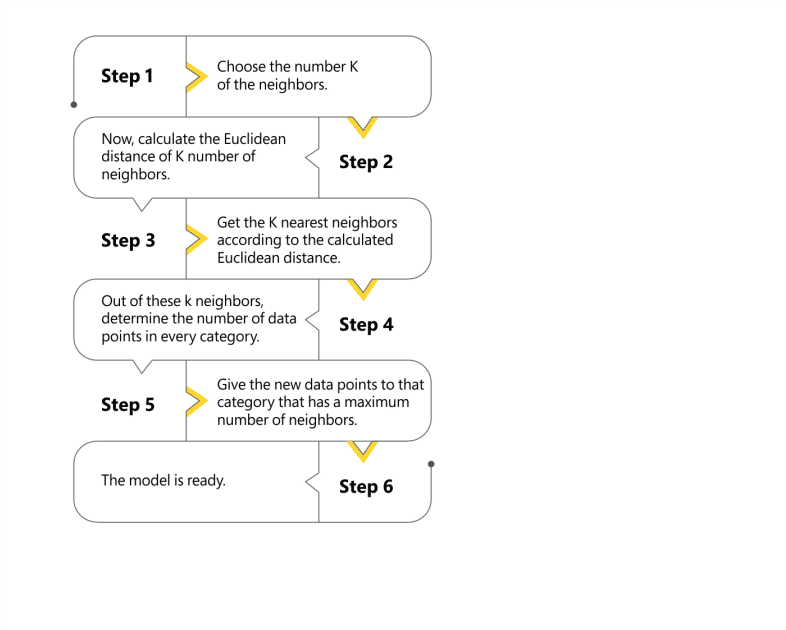
How To Determine the Value of K For the KNN Algorithm?
The value of k is quite important in the KNN algorithm to describe the number of neighbors present in the algorithm.
The value of k in this algorithm must be selected depending on the input data. In case, the input data comprises more noise or outliers or noise, a higher value of k would be ideal.
Pro Tip: It is better if an odd value is selected for k to overcome ties in classification. Cross-validation techniques can assist in choosing the ideal k value for the provided dataset.
When you take any reputed best AI ML certification, you will be taught how to select the value of k by using the KNN algorithm.
Popular Applications of KNN In Machine Learning
Benefits and Drawbacks of The KNN Algorithm
Like any Machine Learning Algorithm, KNN has both its strong and weak points. Based on the project as well as the application, it may or may not be a suitable choice.
Advantages
Disadvantages
Conclusion
The K-Nearest Neighbors Algorithm is easy to understand and fast-to-implement algorithm. While it is a good idea to use libraries and essential tools, developing it from scratch demonstrates how everything happens to work under the hood and offers excellent flexibility. Although the KNN algorithm in machine learning has several shortcomings, it can be resolved by making some modifications and improvements. And this makes it among the most potent classification algorithms available.


